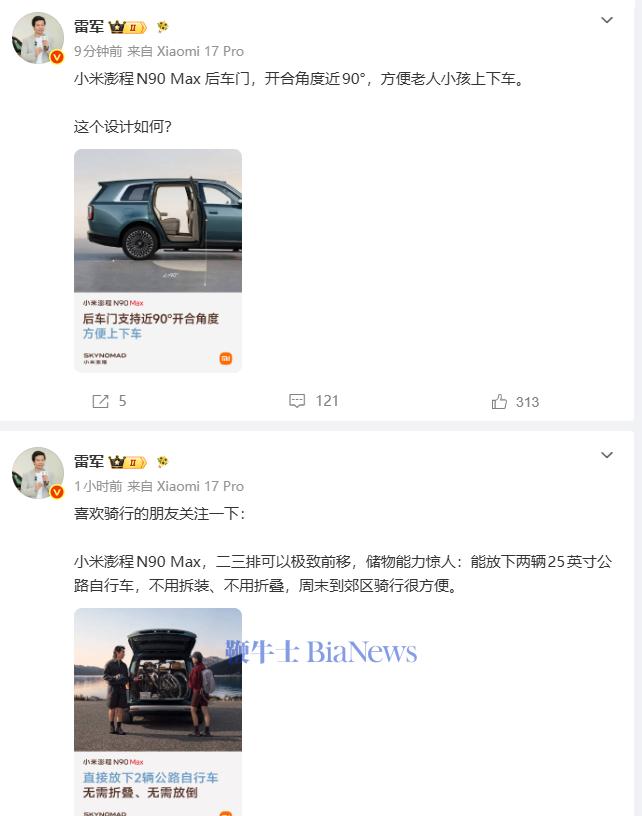
2月10日,腾讯混元推出面向消费级硬件场景的“极小”模型HY-1.8B-2Bit。该模型基于1.8B参数的小尺寸模型,通过2Bit量化技术,等效参数量约为0.3B,实际存储占用仅约600MB,比常用的一些手机应用还小,实现了端侧部署的新突破。

该模型基于混元团队首创的产业级2Bit端侧量化方案,通过对HY-1.8B-Instruct模型进行2比特量化感知训练(QAT)产出,模型大小减少至原始精度模型的1/6,同时在真实端侧设备上生成速度提升2-3倍,可大幅提升使用体验。能力上,模型还保留了原版的思维链,可以为不同复杂度的任务提供相应深度的推理过程。这是业界首个实现2bit产业级量化的端侧模型实践。


左图为HY-1.8B原始精度模型,右图为HY-1.8B-2Bit模型,量化后的模型速度明显更快
随着大语言模型普及,如何将模型在比如手机、耳机或者智能家居设备应用,成为业界难题,尤其不少应用对模型的离线部署、私密性等都有更高的需求,这就需要更多能够在端侧运行的又小又强的模型。端侧部署的展开,本质上是一条在“小而精,快而准”的艰难探索之路,我们既需要模型足够聪明,能应对千变万化的真实需求,又必须将它约束在极其有限的硬件资源内部署并快速推理,这就好像在给模型进行“减脂增肌,减重提质”。
比特(Bit)是计算机存储的最小单位,1比特能表示2种状态(0或1),2比特能表示4种状态,依此类推,一般模型的精度有2比特、4比特、8比特、32比特等表示方法,数值越大模型的精度更高,所占的内存就越大。
虽然2比特量化的精度损失较大,但通过QAT和先进的量化策略,已经能让2比特模型接近全精度模型的性能。在模型能力方面,对比4比特PTQ模型版本数学、代码、科学等指标上表现相当,实现了“小而强”的设计目标。
技术上,量化作为大模型部署上线不可或缺的一环,肩负了降低部署成本与保精度的使命,大部分情况下对于int4、int8、fp8的压缩精度要求,采用PTQ量化策略即可实现几乎无损,但随着原始模型大小的缩小、压缩bit数的进一步降低,PTQ带来的量化损失是巨大的。因此,对于原始模型大小只有1.8B,量化bit数只有2bit的HY-1.8B-2Bit,混元团队采用了量化感知训练策略,这显著提升了量化后模型的性能。
腾讯混元还通过数据优化、弹性拉伸量化以及训练策略创新三个方法来最大限度的提升HY-1.8B-2Bit的全科能力。
部署方面,腾讯混元提供了HY-1.8B-2Bit的gguf-int2格式的模型权重与bf16伪量化权重,对比原始精度模型,HY-1.8B-2Bit 能够灵活用于端侧设备上,该模型也已在 Arm 等计算平台上完成适配,可部署于启用 Arm SME2 技术的移动设备上,并实现高效运行。
在MacBook M4芯片上,HY-1.8B-2Bit 固定了线程数为2测试了不同窗口大小下的首字时延和生成速度,模型选定fp16、Q4、HY-1.8B-2Bit三种gguf格式作为对比,首字时延在1024输入内能够保持3—8倍的加速,生成速度上常用窗口下对比原始模型精度,HY-1.8B-2Bit能够实现至少2倍稳定加速。

在天玑9500上同样进行了测试,对比HY-1.8B-Q4格式首字时延能够加速1.5—2倍,生成速度加速约1.5倍。

当前,HY-1.8B-2Bit的能力仍受限于监督微调(SFT)的训练流程,以及基础模型本身的性能与抗压能力。针对这一问题,混元团队未来将重点转向强化学习与模型蒸馏等技术路径,以期进一步缩小低比特量化模型与全精度模型之间的能力差距,从而为边缘设备上的大语言模型部署开拓更广阔的应用前景。
项目链接:https://github.com/Tencent/AngelSlim
模型地址:https://huggingface.co/AngelSlim/HY-1.8B-2Bit
https://huggingface.co/AngelSlim/HY-1.8B-2Bit-GGUF
技术报告:
https://huggingface.co/AngelSlim/HY-1.8B-2Bit/blob/main/AngelSlim_Technical_Report.pdf




 京公网安备 11011402013531号
京公网安备 11011402013531号