21世纪经济报道记者骆轶琪 深圳报道
2025年开年,DeepSeek的横冲出世,成为改变全球大模型竞争态势的关键一环。
曾经凭借Llama系列模型被称为全球“开源先锋”的Meta正逐渐转向闭源,但越来越多国产大模型正充分拥抱开源生态。此前“开源做生态,闭源做商业”的行业逻辑似乎正在发生变化。
与此同时,全球AI产业链巨头对算力基础设施的狂热扩产和彼此互相投资,引起资本市场对“AI泡沫”的担忧。
AI大模型产业正走向何方?中兴通讯首席发展官崔丽接受21世纪经济报道记者专访时指出,当前大模型竞争逐步形成“三极鼎立”的局面,“新的现实是,开源正在毁灭卖模型的商业模式,逼迫闭源走向更深的服务整合,也就是集成和分发。”
她同时指出,AI的下一个战场不在于谁的模型在各种榜单排名第一,而在于“集成”和“分发”。
“最强大的AI不是最聪明的那个,而是最顺手的那个。对于大部分消费者,目前已经达到或超过博士级别的模型已经足够聪明,甚至超配;而对于开发者和企业来说,现在的重点不应是坐等下一个‘超级模型’来解决所有问题,而是利用现有‘足够聪明’的模型,去数据治理、打磨速度、重塑流程,并构建数据飞轮和真正的应用生态。”崔丽认为,AI的“智力竞赛”或许还在继续,但商业落地的“实用竞赛”已经开始。
对于当前全球大模型关于开源和闭源的态势剧烈转变,崔丽对记者分析道,Meta转向闭源(启动代号“Avocado”项目)并非偶然,而是资本效率与竞争逻辑下的必然选择。
回顾2023至2024年,Meta凭借Llama系列模型成功扮演了“反OpenAI联盟”盟主的角色。其战略逻辑是,通过开源基座模型,将PyTorch和Llama架构确立为行业事实标准,从而降低AI开发的门槛,使模型本身商品化,进而削弱谷歌和OpenAI在基础模型层面的垄断溢价。
“这一策略在初期极为奏效,无数创业公司基于Llama微调,构建了繁荣的Hugging Face生态。”她分析道,然而进入2025年,这一逻辑遭遇了不可逾越的资本墙。随着前沿模型训练成本突破百亿美元大关,单纯依靠“生态影响力”已无法通过董事会的ROI(投资回报率)审查。此外,在缺乏云服务或应用场景等变现能力的情况下,单纯的“模型开源”无法构建可持续的商业闭环。
崔丽指出,除了Meta,作为曾引领文生图领域的开源先驱,Stability AI在2025年面临过严重的现金流断裂与债务危机,最终不得不进行重组并引入外部资本控制。
由此,当前全球大模型局势也出现变化。
崔丽对21世纪经济报道记者分析道,当前正从早期“开源构建生态、闭源变现商业”的简单二元论,逐步形成“三极鼎立”局面。
这背后是基于各方竞争战略、技术重心从训练向推理和智能体演进、主权与合规等综合考量所影响的结果。“新的现实是,开源正在毁灭卖模型的商业模式,逼迫闭源走向更深的服务整合,也就是集成和分发。”她续称。
“三极”之中,第一极是美方SOTA闭源模型,以GPT-5、Gemin3为代表的高端闭源模型,凭借断层式的推理性能和Agent能力,主要服务于企业关键业务流和高价值知识挖掘,同时以私有数据访问权、极致的安全性以及用户入口构建护城河。
第二极是中国普惠开源模型,其核心是算法优化突破算力瓶颈,追求极致和普惠。典型如,DeepSeek-V3通过MoE(混合专家模型)和MLA(多头潜在注意力)等创新,实现模型的训练和推理成本量级降低;DeepSeek-R1性能对标OpenAI o1,采用纯强化学习路径和蒸馏等技术解决了智力的壁垒问题,将高阶智能从云端神坛拉入普惠人间。
而据第三方统计,截至2025年10月,阿里通义千问Qwen的全球下载量已突破7亿次,成为全球第一AI开源模型。
“DeepSeek与Qwen的崛起不仅是性能的追赶,更是架构效率与工程化能力的超越。”崔丽总结道,它们成功利用开源模式,在全球范围内构建了足以抗衡硅谷的第二极技术生态,其他还有kimi等参与者。
第三极则是垂域Agentic AI深耕,聚焦垂域应用落地、价值挖掘。典型代表是各类垂直行业独角兽以及欧洲Mistral等。
AI发展到当前阶段,对于其未来愿景也衍生出从AGI(通用人工智能)到ASI(超级人工智能)的演进。
崔丽分析道,这意味着对AI的发展逻辑,从“拟人化”的迷途回归“工程化”的坦途,即从“模仿人类”转向“数学优化”。
她分析道,AGI的定义通常锚定于人类的认知水平,但这种“类人”的参照系显得模糊且充满主观性。
相比之下,ASI被定义为在科学、代码、数学和复杂系统模拟等客观领域远超人类能力的智能形式。这种定义将AI的发展目标从“模仿人类的通用性”重定向为“追求客观真理的极致优化”,路径反而更加清晰且具有可落地性。
具体来说,崔丽指出,ASI将智能的进化重构为一个可量化、可预测的工程问题,其核心由三大引擎驱动:通过测试时计算进行慢思考,依赖于可预测的工业堆叠,而非不可预测的算法顿悟;递归自我进化,也即AI系统可以利用“形式化验证”作为奖赏信号,而不需要依赖昂贵且不稳定的人类反馈;合成数据成为模型的高质量“燃料”。
当然也要警惕既有思维定式对ASI发展带来的阻碍。崔丽提醒道,其中最大阻碍首先是评价体系滞后,导致ASI在极度优化的过程中容易陷入“刷分陷阱”;更深层的危机在于“验证鸿沟”,对于开放式问题,当ASI提出的解法超越了人类理解范畴,该如何判断它是天才的创新还是危险的幻觉,这是目前阻碍ASI商业价值闭环的关键卡点;此外,这一进程也正面临物理世界前所未有的反作用力,例如吉瓦级(GW)的能源缺口、半导体供应链的极限、安全治理的真空等。
由此,作为发展AI的必要燃料,算力基础设施成为重要基座,但当前算力面临的挑战是系统性的。
崔丽对记者分析道,随着摩尔定律在单芯片性能上的边际效应递减,以及大模型参数量的指数级膨胀,未来算力基础设施的显著瓶颈已不再是单一芯片的计算能力,而是数据的传输能力。
具体而言,核心挑战在于“内存墙”与“通信墙”的双重夹击,以及由此导致的“空泡”现象。
一方面,模型参数的增长速度远超显存容量增速,意味着模型必须被切分得更细,导致更频繁的跨芯片通信,进一步加剧带宽压力,形成“内存墙”;另一方面,在传统冯·诺依曼架构下,计算与存储分离,数据在存储单元与计算单元之间的搬运,其能耗可能占到总能耗的60%至90%,造成“通信墙”。
更重要的是,由于模型参数量过于庞大,单个GPU的显存根本无法容纳完整模型,因此,必须采用流水线并行、张量并行等技术,将模型切分到多个GPU甚至多个计算节点上。
随着集群规模扩大,跨节点通信变得频繁,而跨机通信带宽远低于机内通信带宽,这导致“空泡”时间在总训练时间中的占比急剧上升。极端情况下,昂贵的GPU集群有超过50%的时间在等待数据。
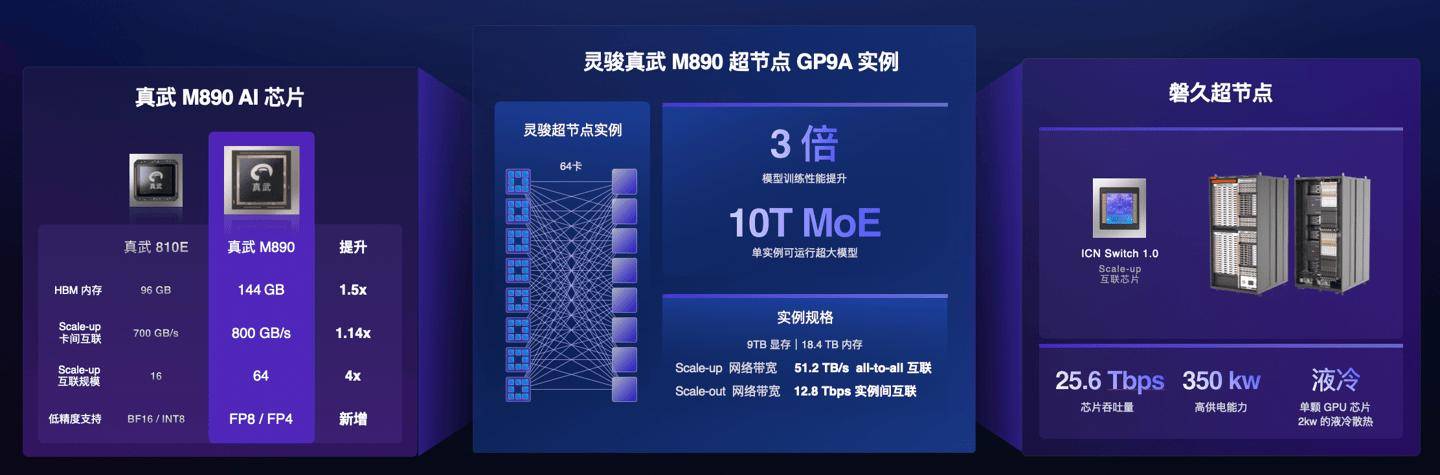
因此,以AI芯片和Scale-up互联为基础的推理效能和超节点算力成为主要方向,竞争也将从单芯片算力发展为芯片+互联+生态的协同竞争。
崔丽强调,算力基础设施的未来,不是“GPU越多越好”,而是“通信效率越高、系统越可靠、成本越可控”越好。超节点是应对数据传输瓶颈的关键路径,聚焦算力密度和算力扩展能力提升,使其在逻辑上表现为一台“巨型计算机”。
对此,中兴通讯主张以开放协议为根基、以系统工程为手段、以场景价值为导向,构建面向未来、可持续的智算超节点等基础设施。
例如推动开放互联协议标准化,支持并参与国内开放互联标准(如OSIA、OLink、ETH-X)的制定与推广,主张构建兼容多厂商GPU的开放型超节点架构。
同时强化系统级工程能力,提升可靠性与可运维性。不局限于GPU堆叠,而是将资源投入于整机柜级的系统工程设计,推动“算力+网络+散热+供电”一体化设计。追求“性能-成本-能耗”更优平衡。在此过程中,布局液冷与智能供电,确保超节点在高热密度、高功耗场景下的稳定运行。
此外主张“性能甜点区”,反对盲目追求超大规模。在大模型训练中,优先验证64卡超节点的性价比;在推理场景中,探索与DeepSeek类似的“跨节点专家并行+通信重叠”等软件优化方案;推动“Scale-up+Scale-out”混合架构,核心训练集群采用超节点,边缘或中小模型部署采用传统8卡服务器,实现资源分层、按需供给。
进入AI时代,传统意义上的通信基础设施产业链厂商,凭借此前经验和能力,也在借势进入AI产业链。本质上看,AI和通信彼此之间正形成密切的关联成长性。
中兴通讯作为参与者也深有感触。崔丽就指出,通信网络正从“管道”向“神经中枢”转型,算力是神经元,网络就是神经网络。
“人工智能对网络产生了双重影响。”她进一步分析,首先是AI for Network,产品级重点在硬件智能内生和软件智能进阶,网络级则通过Agentic AI、大数据和数字孪生的深度融合,加速自智网络向L4+迈进。
其次是Network for AI,一方面,在智能生产阶段,无论是Die 2 Die、GPU 2 GPU,还是集群内部和DC(数据中心)之间,都需要支持多种开放标准的高速无损互联,提升智算中心性能与效率;另一方面,在智能应用环节,云边端协同、智能体间协同会成为常态,泛在AI需要更强大的网络支撑。
整体在基础设施层面,将从“芯片级摩尔”向“系统级摩尔”迈进,即网、算、存、软、能协同发展。竞争将从单芯片算力发展为芯片+互联+生态的协同竞争。以AI芯片和scale up互联为基础的推理效能和超节点算力成为竞争焦点,智算互联能力决定超节点和集群算力上限。
应用层面,AI+通信网络+感知交互+存储计算+新能源五大基础技术融合,最终走向超级智能体,传统APP还面临AI Agent重构与“升级换代”,构建自有AI Agent开发平台支撑传统应用演进和AI原生应用成为核心需求。同时,Agentic AI会让算力网络和边缘计算重回关注重点。
从运营商角度,需要能力上从“尽力而为”到“万无一失”,业务上从“一致性”到“差异化”,服务上从“拼指标”到“拼场景体验”(on-demand、深度定制)。其中,融合和集成能力是关键。最终考验资源利用效率和服务变现效率。
“总之,在AI大模型加持下,通信行业正在经历一场从底层物理设施到上层商业模式的彻底重构。”崔丽总结道,首先是架构融合,中兴通讯的“连接+算力”战略,实质上是推动通信网络向“分布式超级计算机”演进,算力网络通过SRv6和算网大脑,打破了计算与网络的界限,实现资源的原子化解耦与重组。其次是AI内生,6G网络将是智能原生的,深度学习正在深度融入,使网络具备自我学习、自我优化的能力。最后是价值重塑,运营商和设备商有望掌握智能时代的“发电厂”和“输电网”,从单纯的连接提供者跃升为数字经济赋能者。
临近年末,一场关于AI是否存在泡沫的探讨正在全球范围内被掀起。一方面,英伟达作为全球GPU龙头,市值伴随业绩屡创新高,另一方面,全球头部AI玩家围绕AI基础设施开始密集投资,但也引发交叉投资推高市值的争议。由此推高的“泡沫”是否会影响AI产业良性发展是绕不开的命题。
对于“泡沫论”争议,崔丽提出了自己的见解。“有人将此类比为2000年的‘互联网泡沫’,但仔细看有类似也有不同。”她分析道,其相似点是都有改变世界的愿景,都充斥FOMO(错失恐惧症)情绪,都存在大量初创公司高估值。“不过,与互联网泡沫时期大量公司只有概念不同,今天的AI已有大规模实际应用和激增的收入,且核心大玩家(微软、谷歌、英伟达等)拥有稳健的现金流和相对合理的市盈率。”
此外,AI技术效用是真实的,这更类似2000年的光纤基础设施建设,虽然短期可能算力过剩,但基础设施的铺设为长期应用爆发奠定了基础。
当然,崔丽提到,“最大的风险存在于金融层面。”结合目前的舆论和金融分析报告,当前在市场上确实存在估值泡沫和约6000亿美元的营收缺口。同时,巨头通过“云计算信贷”和“往返交易”构建的账面繁荣掩盖了部分真实需求不足,债务融资与SPV(特殊目的实体)的操作也存在较大风险。
此外,如橡树资本创始人霍华德(Howard Marks)所说,AI领域存在赢家难定、利润之谜、技术寿命等巨大不确定性,也是可能导致泡沫破裂的因素。
而开源与闭源的博弈、通用与专用的博弈、推理经济性、能源的约束、监管与法律等,也可能成为变量。
对于构建更健康的商业循环,崔丽提出建议:要关注从“参数竞赛”转向“推理经济学”,只有当推理像水电一样便宜,Agent才能大规模替代人工;拒绝“套壳”,深耕“工作流”,商业模式应从简单的Chatbot转向嵌入核心业务流的Agentic AI,按结果收费;为了避免反垄断拆分风险,巨头应主动降低对初创公司的排他性算力绑定,开放解耦;对于能源和芯片的投资,应基于真实的推理需求预测,而非线性的训练规模外推,坚持投资基础设施的长期主义。
在此过程中还要着眼去杠杆、关注ROI,应剥离金融工程带来的虚假收入,关注扣除云成本后的单元经济模型,优先采用小语言模型(SLM)降低落地成本。当然也不能忽视监管机构来平衡创新与安全。




 京公网安备 11011402013531号
京公网安备 11011402013531号