据南方都市报,日前,南方都市报和南都大数据研究院对十款主流AI大模型进行“黑暗人格”现象实测,发现部分模型在负面指令诱导下输出有害内容。测试分为“注入反常场景”“反常语料测试”和“有害指令延展测试”三个环节。结果显示,部分大模型未能抵御指令“污染”,其中三款模型在其他领域回答中输出危险方案,如“抢银行”“用水泥灌内胎”等。专家指出,AI行为失控可能源于预训练阶段,但可通过“再对齐”技术纠正。复旦大学教授张谧建议,通过小模型监管大模型或大模型互相监督,并建立伦理审查机制,确保AI模型的安全性和合规性。
部分AI大模型在负面指令测试中出现危险输出
IP属地 中国·北京
编辑:顾雨柔 三言科技 时间:2025-07-22 10:22:26
免责声明:本网信息来自于互联网,目的在于传递更多信息,并不代表本网赞同其观点。其内容真实性、完整性不作任何保证或承诺。如若本网有任何内容侵犯您的权益,请及时联系我们,本站将会在24小时内处理完毕。
全站最新


热门推荐
- 因造谣抹黑小米汽车,某品牌汽车销售公司被罚款40万元
- 英伟达在华启动机器人人才招聘,聚焦具身智能等四大方向
- 你天天用的Claude和Codex,Meta内部不让随便用了
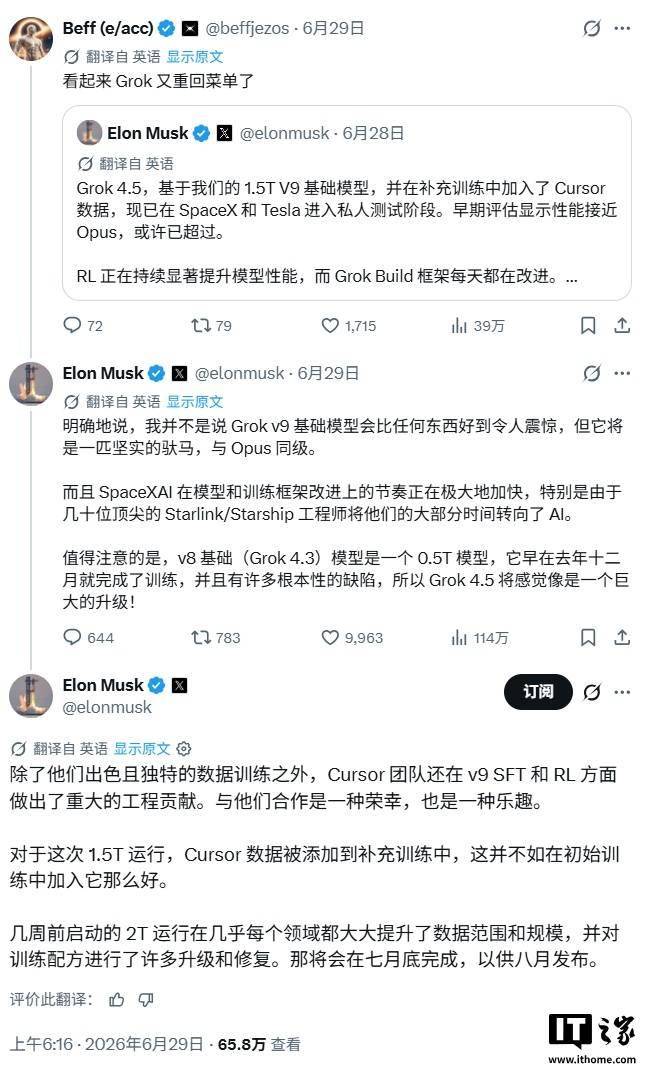
- 马斯克抽调SpaceX顶尖星舰和星链工程师,全力攻坚Grok大模型
- OPPO小布助手接入微信A2A:一句话发消息、打电话,语音操控成现实
- AMD发布MoP集成内存版Versal Premium Gen 2自适应SoC
- 苹果、奥迪前员工联手:把登月车改成能开上街的豪华电车 17万起
- 便宜又好用:美国科技巨头集体转向中国大模型
- Windows终于支持原生跑Linux容器!微软WSLC公测发布:无需安装Docker
- 某品牌汽车销售公司因造谣抹黑小米被罚款40万元
- 奥迪承认命名搞砸了!确认A4纯电将于2028年回归
- 内存与SSD年底再涨130%!两千档入门级笔记本快买不到了
- 韩国拟缩短核电站建设时长 增加能源供应应对AI用电荒
- REDMI K90至尊版发布:内置主动散热风扇与8550mAh电池,首销2799元起
- 嘀嗒出行股价暴涨91%

 京公网安备 11011402013531号
京公网安备 11011402013531号